Linear Regression With R
Linear model in R language to create predictions using data .
In this project will make a linear model in R language to create predictions using our data .
Getting to Know the Data
Before we start working on a linear model, let's see what the data used in this notebook is about.
This data corresponds to **the percentage of the population with access to improved sanitation facilities** and **life expectancy (in years)** in 2014 for 183 countries in the world. It was extracted from [The World Bank](http://data.worldbank.org/) website and pre-processed to eliminate NAs and other issues.
Here, we examine two variables: Access to Sanitation and Life Expectancy.
AccesstoSanitation: Access to improved sanitation facilities refers to the percentage of the population using improved sanitation facilities. Improved sanitation facilities are likely to ensure hygienic separation of human excreta from human contact. They include flush/pour flush (to piped sewer system, septic tank, pit latrine), ventilated improved pit (VIP) latrine, pit latrine with slab, and composting toilet.
Life_Expectancy: Life expectancy at birth indicates the number of years a newborn infant would live if prevailing patterns of mortality at the time of its birth were to stay the same throughout its life.
Importing the Dataset
Run the code cell below to load the data into the dataframe my_data.
my_data <- read.csv("https://ibm.box.com/shared/static/q0gt7rsj6z5p3fld163n70i65id3awz3.csv")
Explore the Data
Let's run the cells below just to see what the dataframe looks like and check its structure.
head(my_data)
| Afghanistan | 31.8 | 60.37446 |
| Albania | 93.2 | 77.83046 |
| Algeria | 87.4 | 74.80810 |
| Angola | 51.1 | 52.26688 |
| Argentina | 96.1 | 76.15861 |
| Armenia | 89.5 | 74.67571 |
str(my_data)
'data.frame': 183 obs. of 3 variables:
$ Country : Factor w/ 183 levels "Afghanistan",..: 1 2 3 4 5 6 7 8 9 10 ...
$ Access_to_Sanitation: num 31.8 93.2 87.4 51.1 96.1 89.5 97.7 100 100 87.9 ...
$ Life_Expectancy : num 60.4 77.8 74.8 52.3 76.2 ...
Visualizing the Data
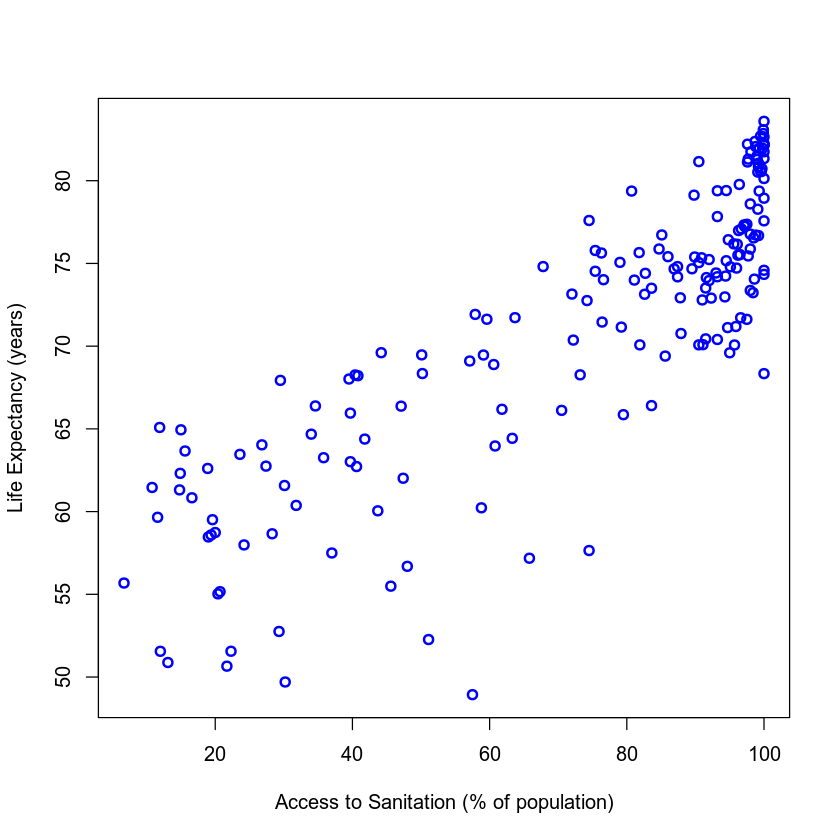
Now it's time to visualize our dataset. Do you think we'll be able to identify any trends?
To begin, let's make a simple scatter plot of Access to Sanitation Facilities and Life Expectancy.
plot(my_data$Access_to_Sanitation, my_data$Life_Expectancy, xlab = "Access to Sanitation (% of population)",
ylab = "Life Expectancy (years)", col = "blue", lwd = 2)
Building a Linear Model
Looking at the plots, were you able to identify any trends? Is there a relationship between Access to Sanitation and Life Expectancy? If so, which is the independent (explanatory) variable and which is the dependent (outcome) variable?
Since access to sanitation is likely to affect one's life expectancy, in our linear model, Access to Sanitation is our independent variable and Life Expectancy is our dependent variable.
Let's learn how we can run a linear regression model in R!
The first argument of lm() has the form "response ~ term". This is what we call formula.
The first element of the formula is the response (dependent variable), and it should have numeric values (continuous variable). As we want to use this model to measure the relationship between Access to Sanitation and Life Expectancy, we should use the dependent variable Life_Expectancy column as response.
The second element, after the "~", is called term (independent variable) corresponding to the independent variable. It is a series of terms specifying a linear predictor for response. In this case, we use the column Access_to_Sanitation.
**What does the linear model do?**
It will try to find a line that best fits the data, according to: $$ Y = aX + b$$
Where **Y** is the **response**, **X** is the **term**, **a** is coefficient that defines the slope and **b** is the intercept with the Y axis.
Creating the Model
Note that before using the function lm() the column that will be used as term must be converted to a vector.
# Create a vector containing the sanitation data
sanitation <- as.vector(my_data$Access_to_Sanitation)
# Build a linear model
model <- lm(Life_Expectancy ~ sanitation, data=my_data)
# Get some information about the model
summary(model)
model
Call:
lm(formula = Life_Expectancy ~ sanitation, data = my_data)
Residuals:
Min 1Q Median 3Q Max
-18.4453 -2.4513 0.3395 3.5113 8.7049
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 53.51021 0.88544 60.43 <2e-16 ***
sanitation 0.24122 0.01129 21.37 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 4.488 on 181 degrees of freedom
Multiple R-squared: 0.7162, Adjusted R-squared: 0.7147
F-statistic: 456.9 on 1 and 181 DF, p-value: < 2.2e-16
Call:
lm(formula = Life_Expectancy ~ sanitation, data = my_data)
Coefficients:
(Intercept) sanitation
53.5102 0.2412
ased on the output, our model was successfully created! Here, you can check the coefficients, the residual error, and some other information as well.
Take a closer look at **"Residuals"**, in the output above. Residual is the difference between the actual data value and the value predicted by the linear model. It is calculated for every data sample - in our case, 183 countries! As it wouldn't be convenient to visualize 183 residuals, what you see above is a summary containing the **Min**, **1Q**, **Median**, **3Q** and **Max** values.
Now look at the **residual standard error**: it's a measure of the model’s accuracy. In our model, the error is 4.488 on 181 degrees of freedom, which is a very good result. **“Degrees of freedom”** are defined as the difference between the number of observations in the sample and the number of variables in the model (183 countries minus 2 variables).
We also have the **"Multiple R-squared”**. This is a statistical measure of how closely the regression line fits the data. Numerically, it’s the percentage of the response (dependent) variable’s variation that is explained by the independent variables. Generally, good models have high values. However, a high R-squared value alone cannot justify the model.
The last item in the output is the **p-value**, which tests the fit of the null hypothesis to our data. The null hypothesis assumes that there is no relationship between the independent and dependent variables in the model. The p-value represents the probability you will obtain a result equal to or more extreme than what was actually observed, if the null hypothesis is true. Generally, if the p-value is very low (below 0.05), it meets threshold to reject the null hypothesis.
Here, the p-value is less than 0.05. We conclude that there is a significant relationship between Access to Sanitation and Life Expectancy.
Plotting the Model
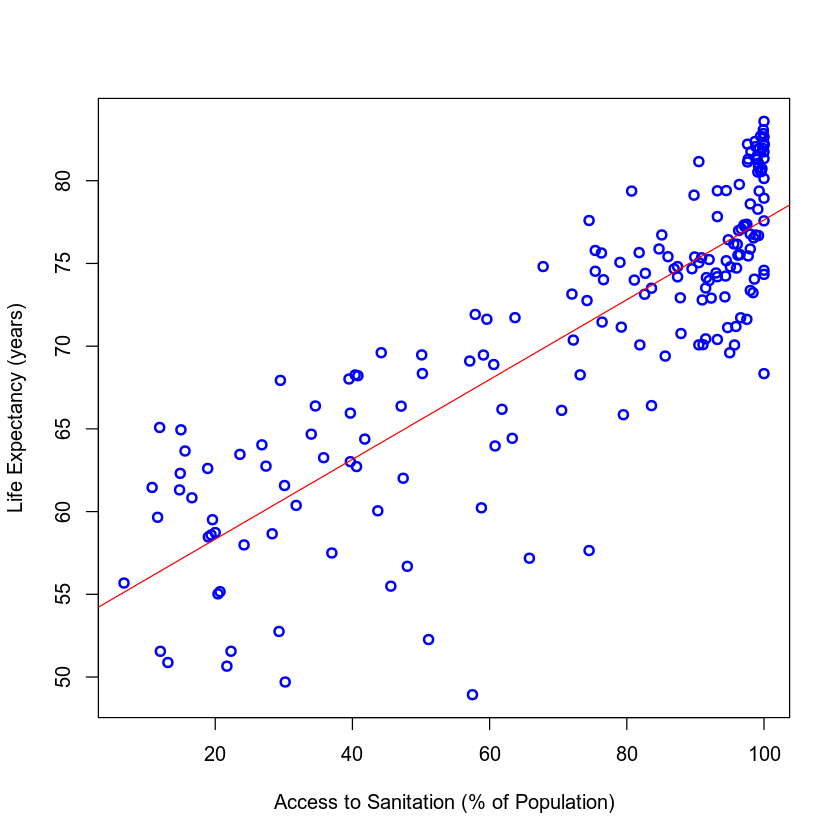
In the code cell below we'll make the same scatter plot we made before, fitting a line to visualize the results of our model.
{
# Plot the previous scatter plot
plot(my_data$Access_to_Sanitation, my_data$Life_Expectancy, xlab = "Access to Sanitation (% of Population)",
ylab = "Life Expectancy (years)", col = "blue", lwd = 2)
# Fit a line in the plot
abline(model, col = "red")
}
Using the Model for Estimations/Predictions
Now that we have a model, we can estimate the Life Expectancy for a given value of Access to Sanitation Facilities that isn't in the dataset. For this, we can use the function predict() and our linear model.
It is interesting to know that predict has a way of calculating the confidence in its own prediction. This means that you can get a 95% confidence interval for the predicted point.
# Tips: using point that fall out of the term interval in the training dataset may lead to errors of prediction that are much larger than expected.
summary(my_data$Access_to_Sanitation)
Min. 1st Qu. Median Mean 3rd Qu. Max.
6.70 47.70 87.40 72.74 97.35 100.00
# Create points to predict, use the point that fall between 6.70 and 100.00
pointsToPredict <- data.frame(sanitation = c(10, 42))
#Use predict() to compute our predictions!
predictionWithInterval <- predict(model, pointsToPredict, interval = 'prediction')
predictionWithInterval
| 55.92236 | 46.93336 | 64.91136 |
| 63.64124 | 54.73514 | 72.54735 |
Let's add our estimations to the previous plot!
In the output above you can see that fit is the prediction value, as we have already seen before. The upper and lower bounds for the interval are lwr and upr.
Let's plot this:
{
# Plot the previous scatter plot
plot(my_data$Access_to_Sanitation, my_data$Life_Expectancy, xlab = "Access to Sanitation (% of Population)",
ylab = "Life Expectancy (years)", col = "blue", ylim=c(45, 85), lwd = 2)
# Add the new predicted points!
points(pointsToPredict$sanitation, predictionWithInterval[,"fit"], col = "red", lwd = 4)
points(pointsToPredict$sanitation, predictionWithInterval[,"lwr"], col = "firebrick4", lwd = 4)
points(pointsToPredict$sanitation, predictionWithInterval[,"upr"], col = "firebrick4", lwd = 4)
legend("topleft",legend = c("Dataset Points", "Prediction Points"), fill = c("blue","red"), bty = "n")
# Fit a line in the plot
abline(model, col = "red")
}

